Multimodal End-to-End Sparse Model for Emotion Recognition
This is a paper accepted in NAACL 2021 [PDF].
Introduction
The existing works in multimodal affective computing tasks, such as emotion recognition, generally adopt a two-phase pipeline approach (Zadeh et al., 2018; Tsai et al., 2018, 2019; Rahman et al., 2020) which first extracting feature representations for each single modality with hand-crafted algorithms and then performing end-to-end learning with the extracted features. This often leads to complication in designing and choosing the best extraction algorithm and sub-optimal performance of the model because of the feature is very sparse and not tunable. In this blog post, we introduce a sparse model that allows end-to-end learning from raw text, audio, & video altogether with only a single 1080Ti GPU. We compare our proposed method with two different approaches, the first one is the two-phase pipeline model with hand-crafted features and the second one is the fully end-to-end model.

As shown on the figure above, hand-crafted algorithm such as OpenFace and OpenCV only capture a small set of keypoints and extract higher level features from the relation between those points. This might produce a fine-grained intuitive representation, although it might not capture all the required points and difficult to be updated, as it needs to be manually tuned. On the contrary, fully end-to-end (FE2E) models enable us to consider all the points in order to extract higher level features. This makes a fully end-to-end model the exact opposite of hand-crafted algorithm, as it might not produce a very intuitive representation but it can capture all the points needed and the model can adjust which point to extract according to the goal of the task. In terms of computation resources, fully end-to-end model generally requires more computation than the hand-crafted counterpart as it takes into account all the points in the image. We try to take both advantage from both methods and invent Multimodal End-to-end Sparse Model (MESM) that not only use less computation than end-to-end model, but also provides an intuitive explaination of what feature is extracted from a given image. We utilize convolution neural network (CNN), Sparse CNN and Transformer as the backbone of our model. The architecture of our sparse end-to-end model is shown on the following figure:
In the above figure, we can see that our sparse end-to-end model is divided into 3 main pathways, one for each modality. For text modality, we encode the text with subword tokenization and feed the tokens into a transformer model. For audio and video signal, we use a single layer 2D convolution neural network (CNN) to extract low level features from the image and perform feature extraction with 3 layers of Cross-modal Sparse CNN block and then feed the extracted features into a small transformer model. To generate the final prediction, we first standardize the feature dimension for all modalities with a feed-forward network and then we combine all of the features with a multimodal fusion layer, which calculate the linear combination from all the extracted features for each predicted class.
Cross-modal Sparse CNN
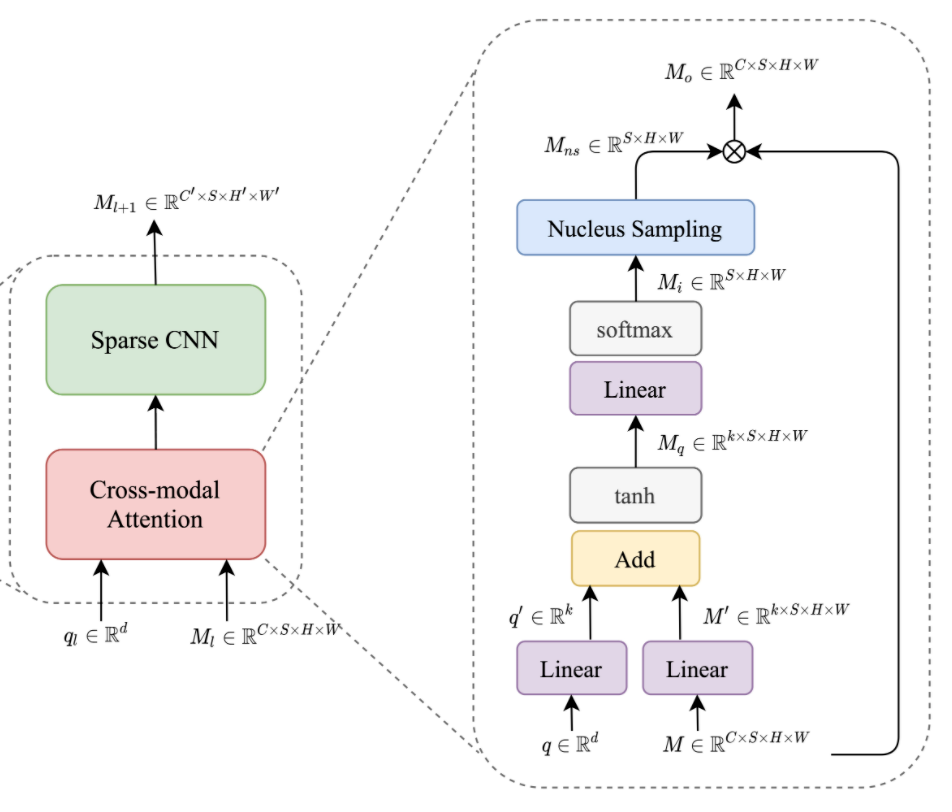
Our cross-modal Sparse CNN block consist of two main components which are a Cross-modal attention layer and a Sparse CNN layer. Our cross-model attention layer is used to extract the important point on the audio and video modalities and then pass only the remaining points into sparse CNN for further processing.
Cross-modal attention
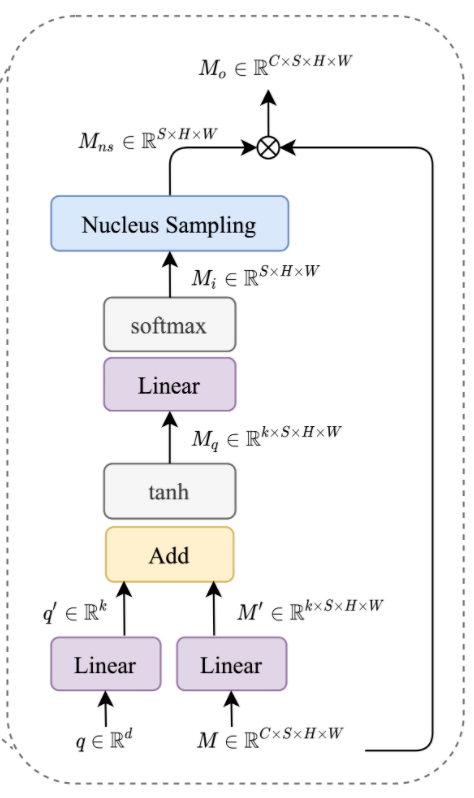
Our cross-modal attention layer is used to filter out unnecessary from audio and video modalities by calculating attention from the text modality to the audio and video modalities. We utilize additive attention mechanism (Bahdanau et al., 2015) over a pair of modalities to compute the attention score. From the resulting attention score, we perform nucleus / top-p sampling with a threshold hyperparameter p.
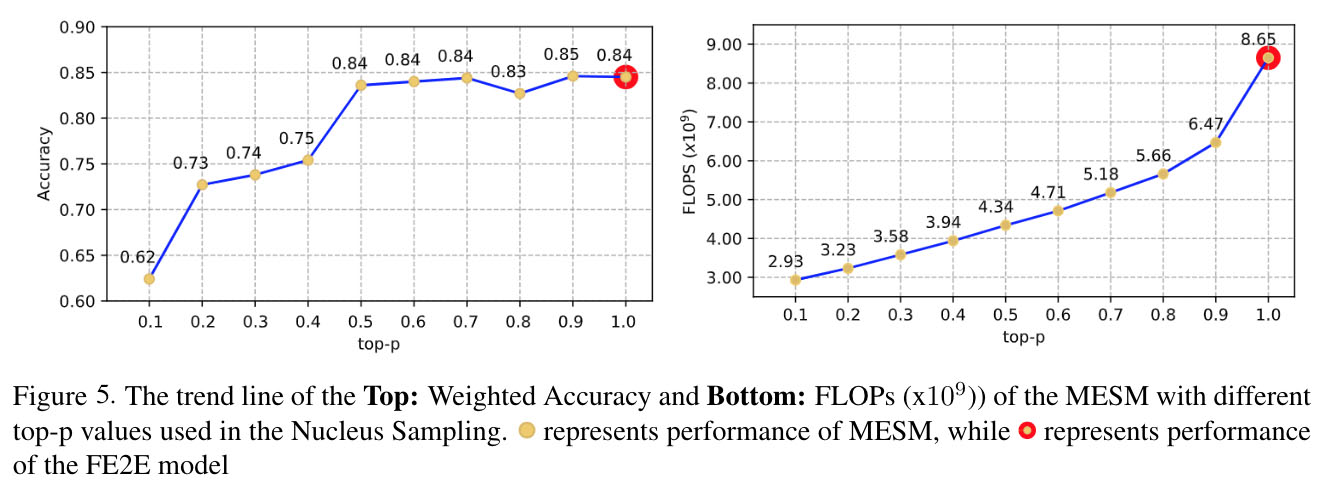
We further conduct a deeper analysis to measure the effect of hyperparameter p to the model quality and computational cost required by the model as shown on the following figure
Sparse CNN
Sparse CNN is introduced by (Graham et al., 2017, 2018). Sparse CNN is specifically made to avoid unnecessary computation in a sparse tensor that will happen when we use a traditional CNN layer. The following figure shows the different between a traditional CNN layer and a sparse CNN layer. * image is taken from https://github.com/facebookresearch/SparseConvNet


Results & Analysis
* We run our end-to-end experiment in 2 datasets, IEMOCAP & CMU-MOSEI, but as some of the raw data from the provided original dataset has been removed, we reorganize the dataset and generate a new dataset split for both datasets. Please go to our paper for more detail about the dataset reorganization and the setup of our experiment
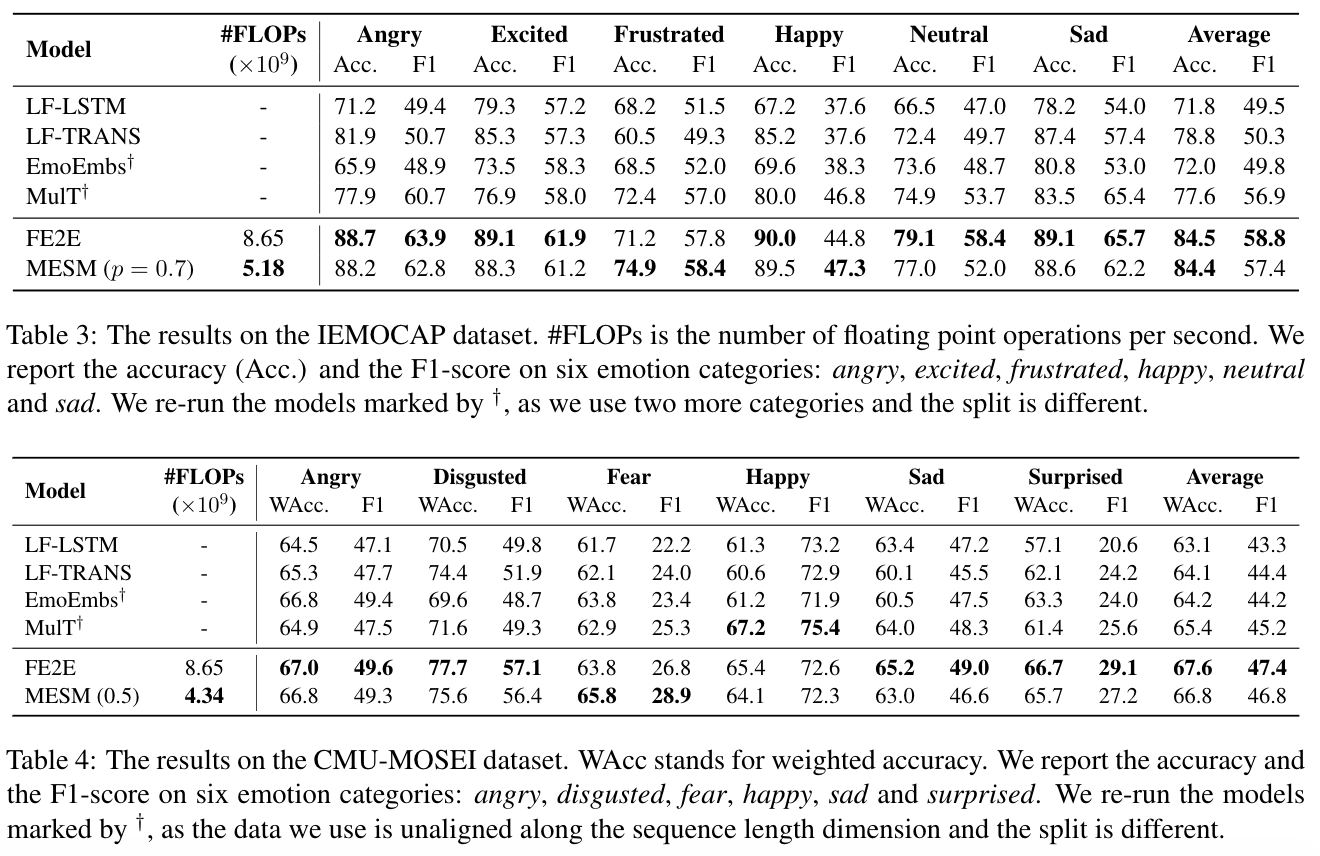
From the experimental results and ablation study, we observe that:
- End-to-end models, both Fully End-to-End (F2E2E) modeland our proposed Multimodal End-to-End Sparse Model (MESM) shows superiority compared to the two-phase pipeline models (LF-LSTM, LF-TRANS, EmoEmbs, and MulT).
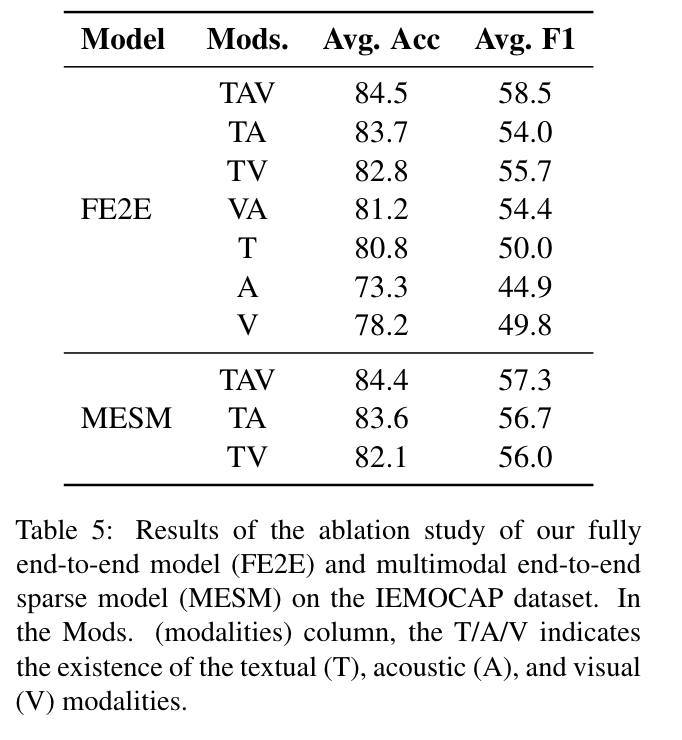
- Our MESM achieves slightly lower results compared to the FE2E model, while requiring less than 60% of the F2E2E model computational cost.
- In two modalities settings, our MESM can achieve a performance that is on par with the FE2Emodel or is even slightly better.
Case Study


For image data, We verify the interpretability of our cross-modal attention by comparing the attention result with the actual Facial Action Coding Systems (FACS) (Ekman et al., 1997, Basori, 2016, Ahn and Chung, 2017) and we can confirm that our attention captures the necessary regions quite well, although it is sometimes fail to capture several features mentioned on the literatures.
For audio signal, we cannot find any reference on how a sound wave looks like for a specific emotion. In general, at the first layer, the sparse attention capture the area with high spectrum value, meaning there is actually a sounds on that particular frequency, and then start to filter out the features and produce a more sparse feature set from one layer to another.
Conclusion
In this work, we first compare and contrast the two-phase pipeline and the fully end-to-end (FE2E) modelling of the multimodal emotion recognition task. Then, we propose our novel multimodal end-to-end sparse model (MESM) to reduce the computational overhead brought by the fully end-to-end model. Additionally, we reorganize two existing datasets to enable fully end-to-end training. The empirical results demonstrate that the FE2E model has an advantage in feature learning and surpasses the current state-of-the-art models that are based on the two-phase pipeline. Furthermore, MESM is able to halve the amount of computation in the feature extraction part compared to FE2E, while maintaining its performance. In our case study, we provide a visualization of the cross-modal attention maps on both visual and acoustic data. It shows that our method can be interpretable, and the cross-modal attention can successfully select important feature points based on different emotion categories. For future work, we believe that incorporating more modalities into the sparse cross-modal attention mechanism is worth exploring since it could potentially enhance the robustness of the sparsity (selection of features).