Language Model as Few-Shot Learners for Task-Oriented Dialogue Systems
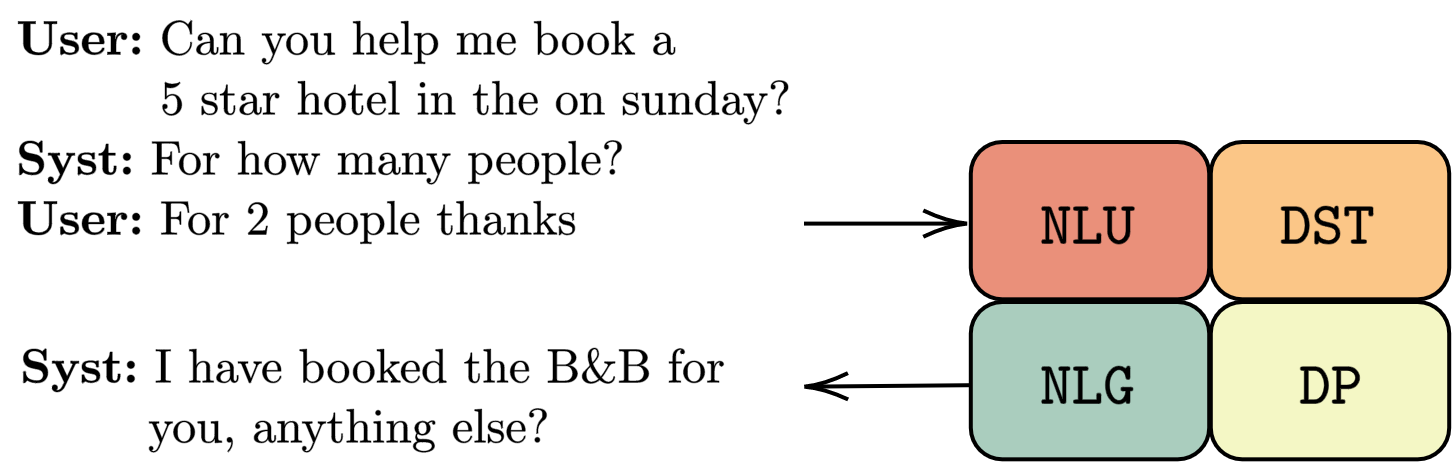
Modularized task-oriented dialogues systems are the core of the current smart speaker generation (e.g., Alexa, Siri etc.). The main modules of such systems are Natural Language Understanding (NLU), Dialogue State Tracking (DST), Dialogue Policy (DP) and Natural Language Generation (NLG), each of which is trained separately using supervised and/or reinforcement learning. Thus a data collection process is required, which for some of the tasks can be laborious and expensive. For example, dialogue policy annotation has to be done by an expert, better by a professional linguist. Therefore, having a model that requires only few samples to actually perform well in the tasks is essential.
The most successful approach in few-shot learning for task-oriented dialogue systems is notably transfer learning, where a large model is firstly pre-trained on a large corpus to be then fine-tuned on specific tasks. For task-oriented dialogue systems, Wu et. al 2020 proposed TOD-BERT a large pre-trained model which can achieve better performance than BERT in few-shots NLU, DST and DP. Liu et. al. 2019 proposed a two-step classification for few-shot slot-filling, a key task for the NLU module. Similarly, Peng et. al. 2020 introduced a benchmark for few-shot NLG and a pre-trained language model (SC-GPT) specialized for the task. Further, a template rewriting schema based on T5 (Raffel et al., 2019) was developed by Kale et.al. 2020 for few-shot NLG in two well-known datasets. Peng et. al. 2020 proposed a pre-trained language model (LM) for end-to-end pipe-lined task-oriented dialogue systems. In their experiments they showed promising few-shot learning performance in MWoZ (Budzianowski et al., 2018).
For performing few-shot learning, existing methods require a set of task-specific parameters since the model is fine-tuned with few samples. Differently, in this paper, we perform few-shot learning by priming LMs with few-examples (Radford, et.al. 2018, Brown TB et.al, 2020). In this setting, NO parameters are updated, thus allowing a single model to perform multiple tasks at the same time. In this blog, we evaluate the few-shot ability of LM priming on the four task-oriented tasks previously mentioned (i.e., NLU, DST, DP, and NLG).
Currently, GPT-3 is not available to the public, or at least not to us now 🙈; thus we experiment on different sizes GPT-2 models such as SMALL (117M), LARGE (762M), and XL (1.54B). All the experiments are run on a single NVIDIA 1080Ti GPU.
Priming the LM for few-shot learning
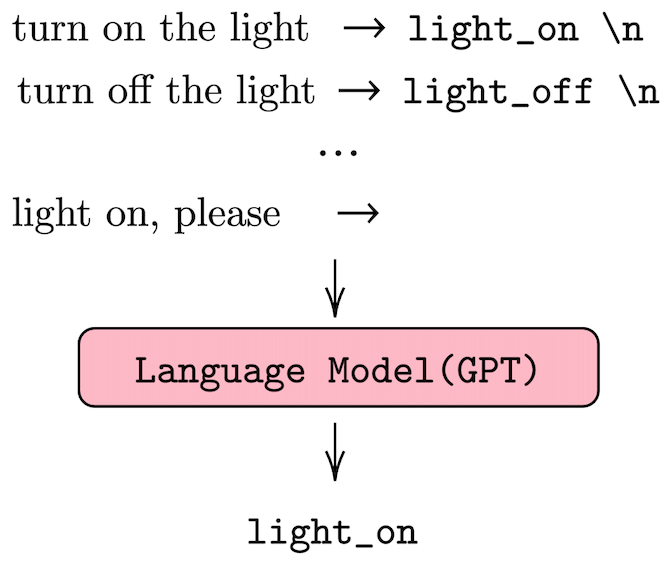
Differently from fine-tuning, few-shot learning with LMs requires designing prefixes to perform few-shot learning (Radford, et.al. 2018, Brown TB et.al, 2020). These prefixes are provided to the LM and the generate token become the actual prediction, Figure 2 shows an example for the intent recognition task. In our four tasks, we use three categories of prefixes: binary, value-based and generative –check the main paper for more information–. We use different prefix styles depending on the task and we compare the results of LM few-shot priming with those of the existing finetuning-base models. In all the experiments, we use different number of shots since different tasks may fit more or fewer samples in the 1024 max input size of GPT-2.
NLU
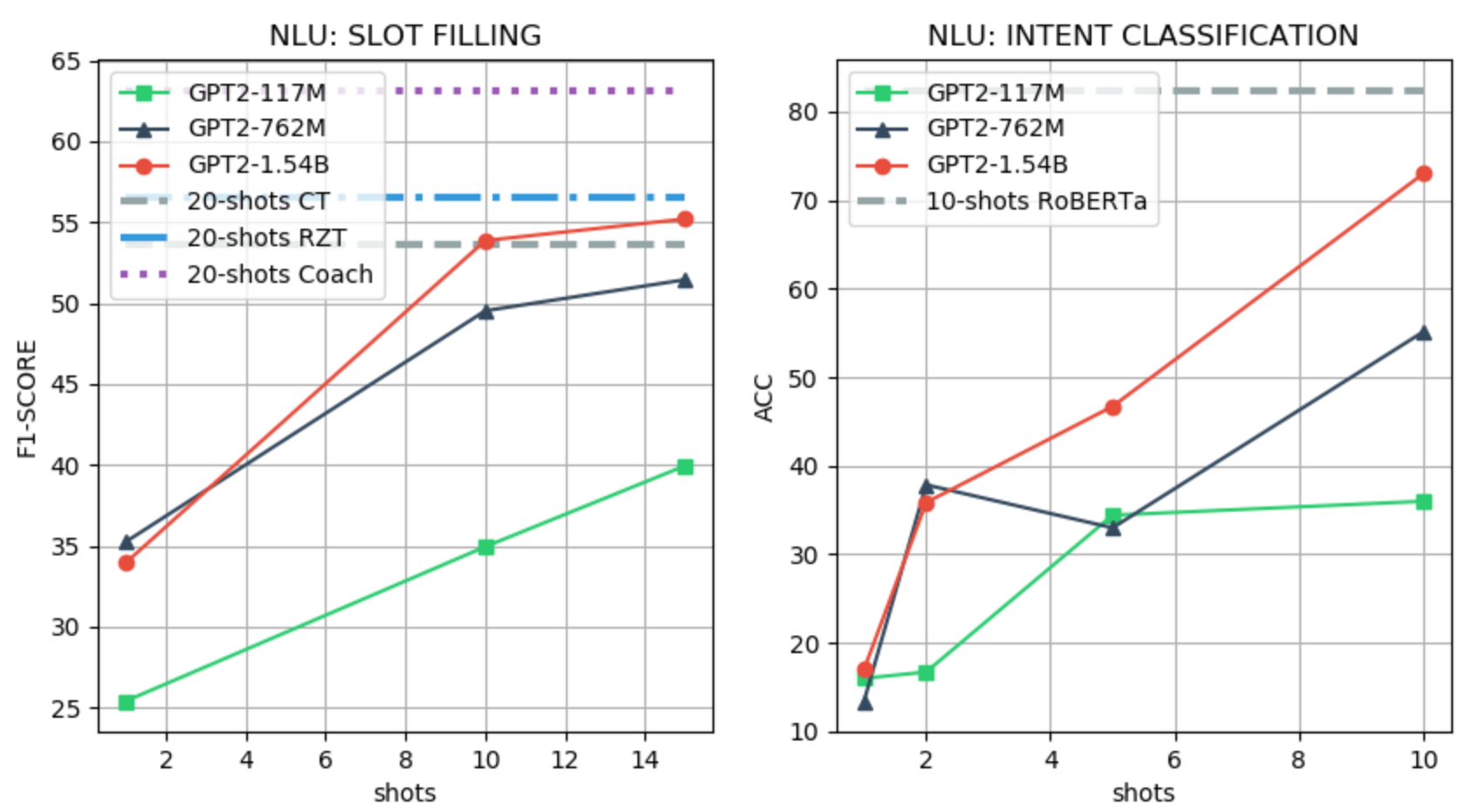
We use the SNIPS (Coucke et al., 2018) dataset for evaluating the SLOT-FILLING and INTENT recognition tasks. For the SLOT-FILLING task, we follow the few-shot setting of Liu et. al. 2019, and we use the official CoNLL F1 scorer as the evaluation metric. For the INTENT classification, we fine-tune RoBERTa (Liu et al. 2019) with 10 samples and use accuracy as the evaluation metric. We use a value-based LM prefix for the SLOT-FILLING task with a maximum of 15 shots, and binary LM prefix for the INTENT classification task with a maximum of 10 shots. An example of a prefix for the two tasks and the few-shot performance evaluation are shown in the Figure below.
add tune to my hype playlist => entity_name = none\n
add to playlist confidence boost here comes => entity_name = here comes \n
add the track bg knocc out to the rapcaviar playlist => entity_name =
listen to westbam alumb allergic on google music => playmusic = true\n
rate this novel 4 points out of 6 => playmusic = false\n
add sabrina salerno to the grime instrumentals playlist => playmusic =
DST
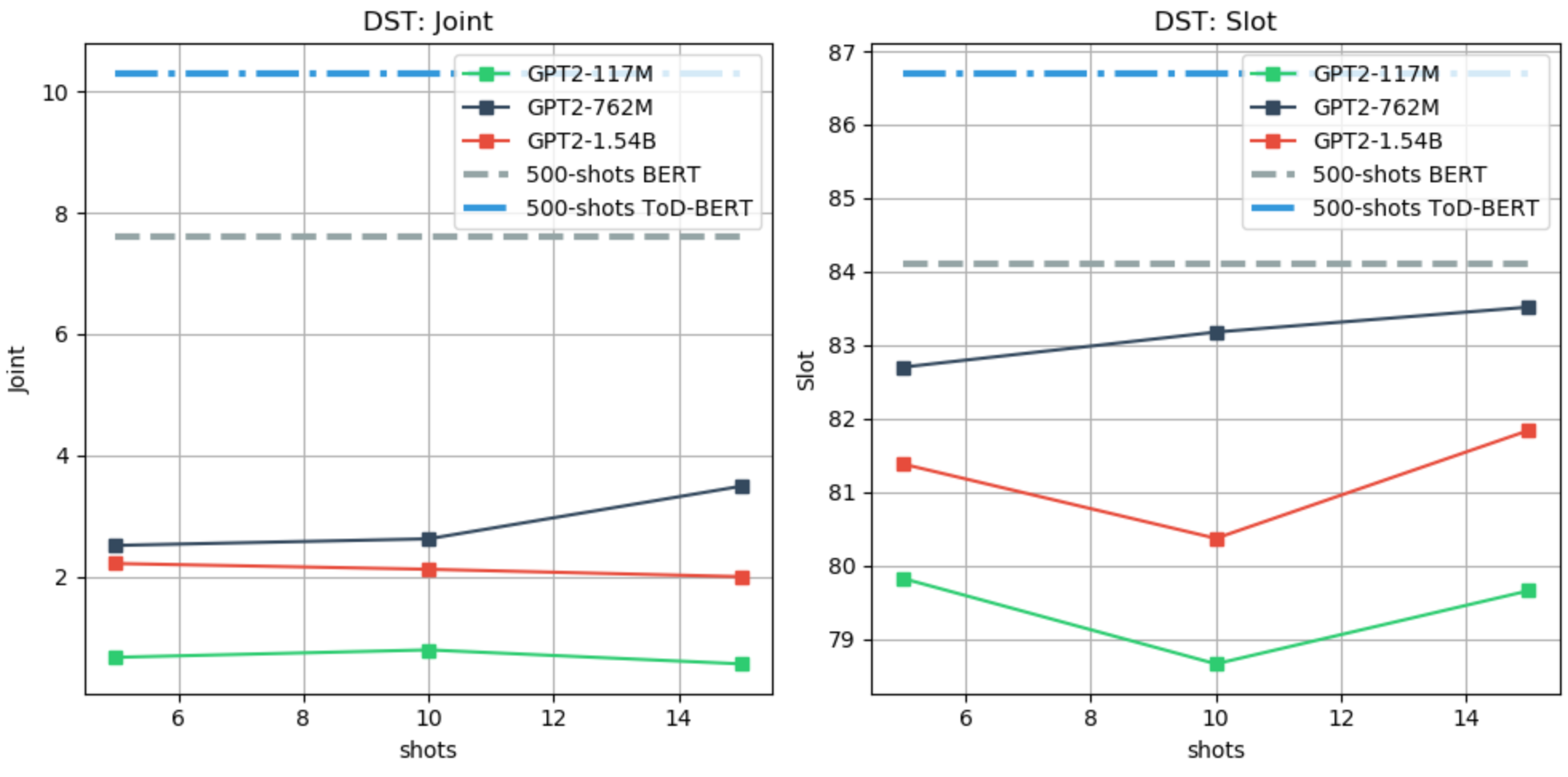
We use the MultiWoZ (Budzianowski et al., 2018) dataset for evaluating the DST task. Differently from other works, we use the last user utterance only as input to the model, and we update the predicted-DST through turns. For the few-shot evaluation, we follow the setting of Wu et. al 2020, and we report the joint and slot accuracy. As baselines, we use TOD-BERT and BERT fine-tuned with 10% of the training data, which is equivalent to 500 examples. We use a value-based LM prefix, as for the SLOT-FILLING task, with a maximum of 15 shots due to limited context. An example of a prefix and the few-shot performance evaluation are shown in the Figure below.
i need a cab by 12:30 too the contact # and car type will be most helpful => leave_at = 12:30 \n
i would like the taxi to pick me up from the hotel . i need to be at the restaurant at 18:30 . => leave_at = none\n
i would like a taxi from saint john s college to pizza hut fen ditton . => leave_at =
ACT
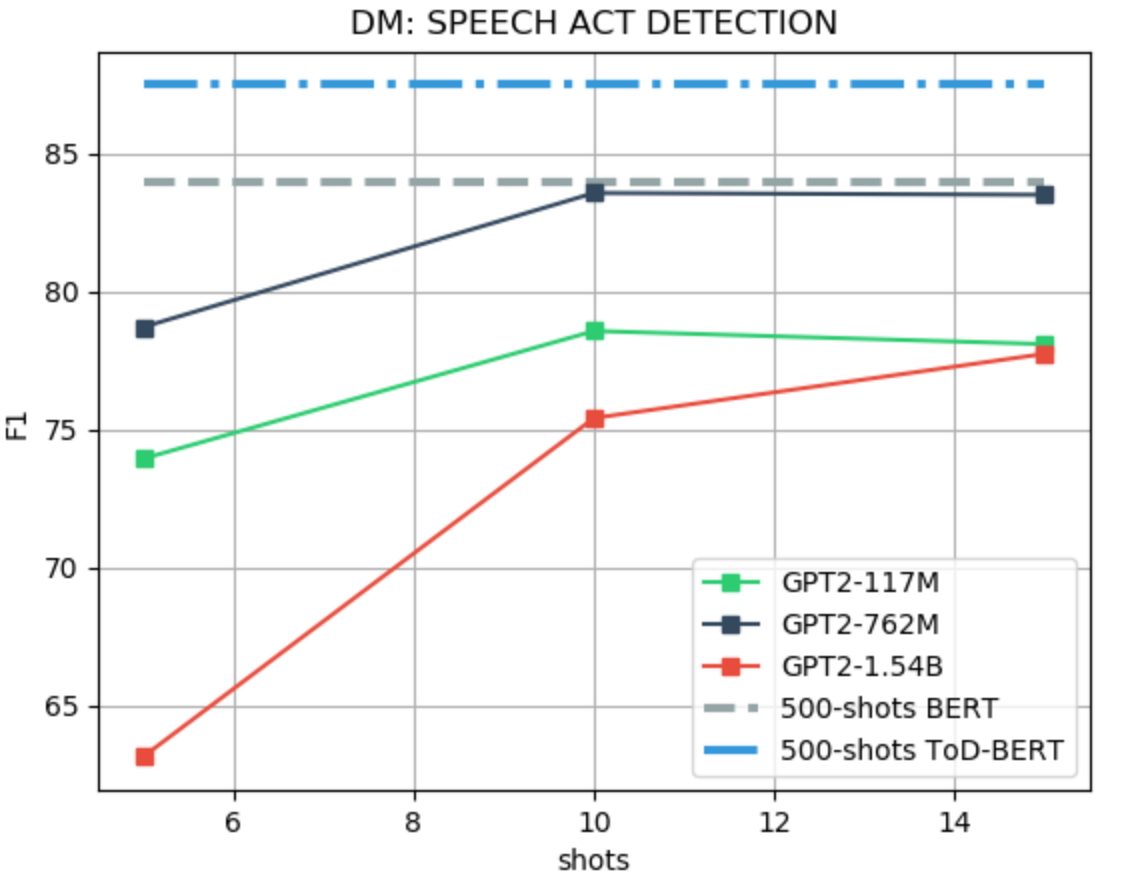
We use the MultiWoZ (Budzianowski et al., 2018) dataset for evaluating the speech ACT identification task. Differently from other works, only the system utterance is used as input to the model, instead of including the dialogue history and the user utterance as in Wu et. al 2020. For the few-shot evaluation, we follow the setting of Wu et. al 2020, i.e., F1-score. As baselines, we use TOD-BERT and BERT, fine-tuned with 10% of the training data, which is equivalent to 500 examples. We use a binary LM prefix, as for the intent classification task, with a maximum of 15 shots due to limited context. An example of a prefix and the few-shot performance evaluation are shown in the Figure below.
yes your booking is successful and your reference number is ri4vvzyc . => offerbooked = true\n
what type of food are you looking for ? => offerbooked = false \n
i do not seem to be finding anything called nusha . what type of food does the restaurant serve ? => offerbooked =
NLG
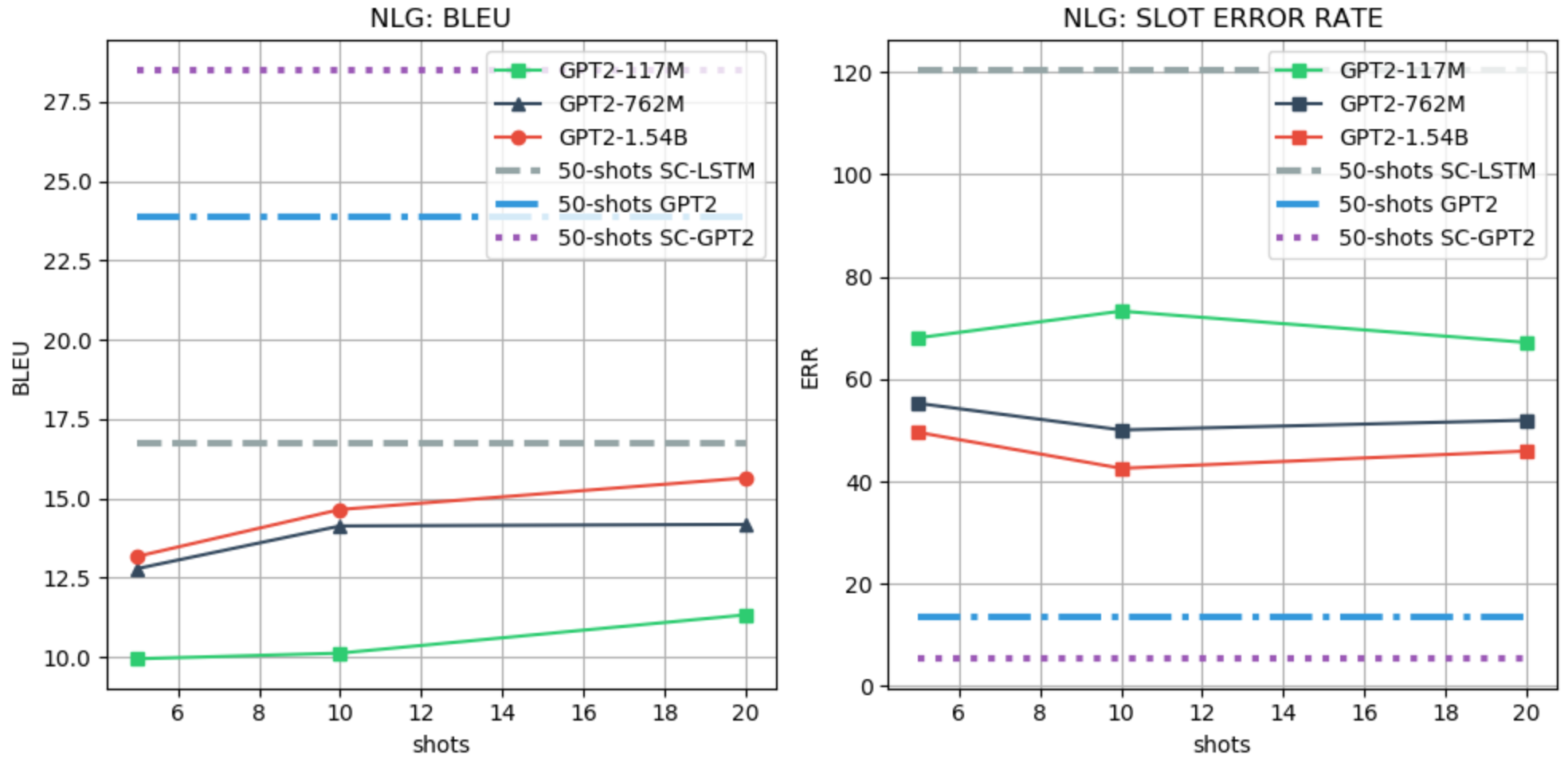
We use the FewShotWOZ (Peng et. al. 2020) dataset for evaluating the NLG task. For the few-shot evaluation, we follow the setting of Peng et. al. 2020 and use the BLEU and slot error rate (SLR) as metrics. We use SC-LSTM, GPT-2, and SC-GPT-2 (Peng et. al. 2020) as baselines, all fine-tuned with 50 examples from the training data. We use a generative LM prefix with a maximum of 20 shots due to limited context. An example of a prefix and the few-shot performance evaluation are shown in the Figure below.
inform(name='hilton san francisco financial district';area='chinatown') => the hilton san francisco financial district is near chinatown\n
inform(name='ocean park motel';dogsallowed='none';phone='4155667020') => the phone number for ocean park motel is 4155667020 . no dogs are allowed there \n
inform(name='super 8 san francisco';phone='8005369326') =>
Analysis and Limitation
From the experimental results, we observe that:
- The larger the model the better the performance in both the NLU and NLG tasks, while, instead, in the DST and ACT tasks, GPT-2 LARGE (762M) performs better than the XL (1.54B) version. This is quite counterintuitive given the results reported for GPT-3. Further investigation is required to understand whether changing the prefix can help to improve the performance of larger models;
- In the NLU, ACT and NLG, LM priming few-shot learning shows promising results, achieving similar or better performance than the weakest finetuning-based baseline, which also uses a larger number of shots. On the other hand, in DST the gap with the existing baseline is still large.
We also observe two limitations of the LM priming:
- Using binary and value-based generation requires as many forwards as the number of classes or slots. Although these forward passes are independent, achieving few-shot learning this way is not as effective as directly generating the class or the tag (e.g., NLU). In early experiments, we tried to covert all the tasks into a generative format, thus making the model directly generate the sequence of tags or the class label. Unfortunately, the results in the generative format were poor, but we are unsure if larger LMs such as GPT-3 can perform better.
- The current max-input length of GPT-2 (1024 tokens) greatly limits the number of shots that can be provided to the model. Indeed, in most of the tasks, no more than 15 shots can be provided, thus making it incomparable with existing models that use a larger number of shots.
Conclusion
In this short blog, we demonstrate the potential of LM priming few-shot learning in the most common task-oriented dialogue system tasks (NLU, DST, ACT and NLG). Our experiments show that in most of the tasks larger LMs are better few-shot learners, confirming the hypothesis in Brown TB et.al, 2020 and, in some cases, they can also achieve similar or better results than the weakest finetuning-based baseline. Finally, we unveil two limitations of the current LM priming few-shot learning the computational cost and the limited word context size.
Acknowledgements
I would like to thanks Jason Wu for providing an easy to use code in ToD-BERT and for clarification about the code and tasks, Baolin Peng for the easy to use repository FewShotNLG and for providing help with the scorer, and Sumanth Dathathri for the discussion and insight about the limitation of the LM priming few-shots.