CrossNER: Evaluating Cross-Domain Named Entity Recognition
Motivation of CrossNER
We Need Cross-Domain NER Models
Named entity recognition (NER) is a key component in text processing and information extraction. Contemporary NER systems rely on numerous training samples and a well-trained NER model could fail to generalize to a new domain due to the domain discrepancy. However, collecting large amounts of data samples is expensive and time-consuming. Hence, it is essential to build cross-domain NER models that possess transferability to quickly adapt to a target domain by using only a few training samples.
We Need a Better Benchmark to Evaluate Cross-Domain NER Models
There are two drawbacks when utilizing existing datasets for cross-domain NER evaluation. First, most targetdomains are either close to the source domain or not narrowed down to a specific topic or domain. Second, the entity categories for the target domains are limited. To this end, we collect a cross-domain NER dataset (CrossNER), a fully-labeled collection of NER data spanning over five diverse domains (politics, natural science, music, literature and artificial intelligence) with specialized entity categories for different domains. Additionally, we also provide a domain-related corpus since using it to continue pre-training language models (domain-adaptive pre-training (DAPT)) is effective for the domain adaptation (Gururangan et al. 2020).
The CrossNER Dataset
To collect CrossNER, we first construct five unlabeled domain-specific (politics, natural science, music, literature and AI) corpora from Wikipedia. Then, we extract sentences from these corpora for annotating named entities. We consider Reuters News from CoNLL2003 as the source domain data.
Data Examples

- CrossNER data examples across the five domains.
- Each domain has its specialized entity categories.
Data Statistics and Entity Category
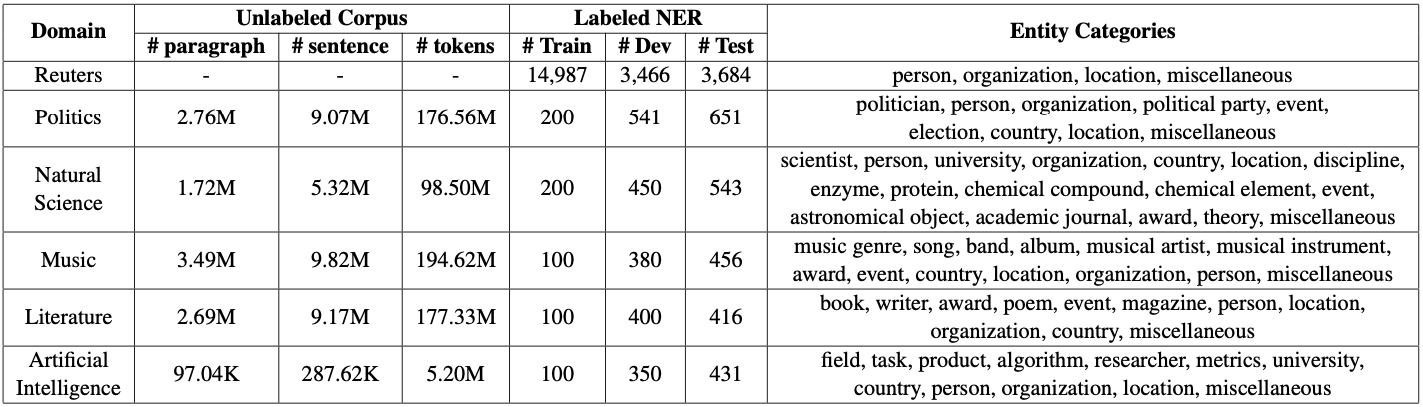
- We keep a small size of data samples (100 or 200) in the training set for each domain since we consider a low-resource scenario for target domains.
- Each domain has its own specialized entity categories.
Domain Overlaps
Vocabulary overlaps between domains (%). Reuters denotes the Reuters News domain, “Science” denotes the natural science domain and “Litera.” denotes the literature domain.
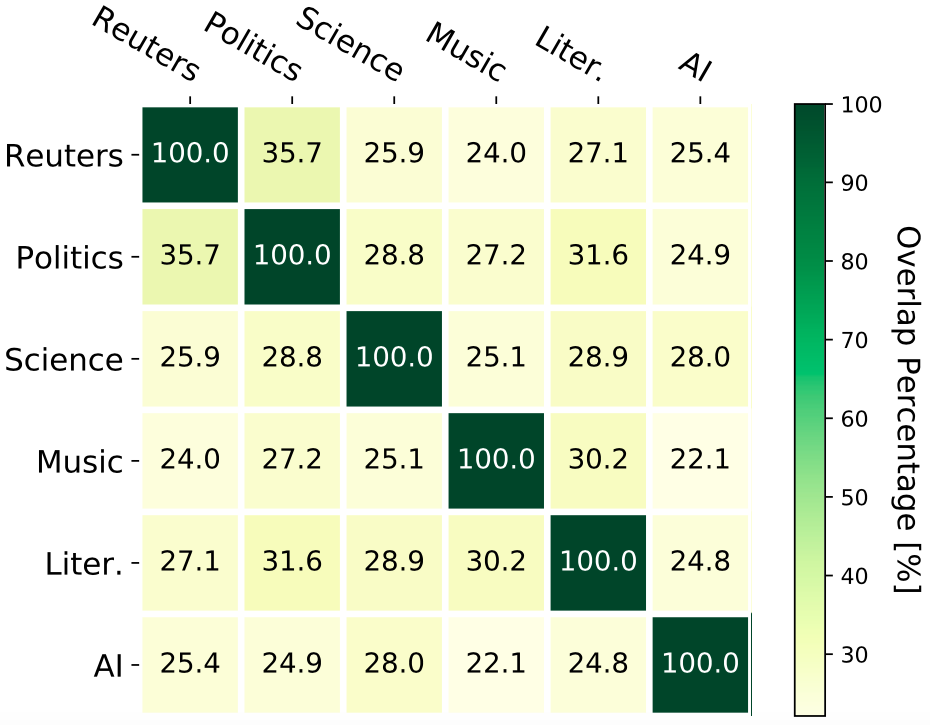
- Overlaps between domains are generally small, which shows the diversity of the target domains.
Domain-Adaptive Pre-Training (DAPT)
We continue pre-training the language model BERT on the unlabeled corpus (i.e., DAPT) for the domain adaptation. The DAPT is explored in two directions. First, we investigate how different levels of the corpus influences the pre-training. Second, we explore the effectiveness between token-level and span-level masking in the DAPT.
Pre-training Corpus
DAPT on a enormous corpus is time-consuming. And there would be noisy and domain-unrelated sentences in the collected coprus. Therefore, we investigate whether extracting more indispensable content from the large corpus for DAPT can achieve comparable or even better cross-domain performance. We investigate four levels of the pre-training corpus.
- Domain-level: The largest corpus we can collect related to a certain domain.
- Entity-level: A subset of the domain-level corpus and made up of sentences having plentiful entities. Practically, it can be extracted from the domain-level corpus based on an entity list.
- Task-level: It is explicitly related to the NER task in the target domain. To construct this corpus, we select sentences having domain-specialized entities.
- Integrated: We integrate the entity-level and the task-level corpus. Concretely, we first upsample the task-level corpus (double the size in practice) and then combine it with the entity-level corpus.
Number of tokens of different corpus types is shown as follows. The number in the brackets represents the size ratio between the corresponding corpus and the domain-level corpus.

Span-level Pre-training
Based on MLM in BERT, we move the individual masked index position into its adjacent position that is next to another masked index position in order to produce more masked spans, while we do not touch the continuous masked indices (i.e., masked spans). For example:
Western music’s effect would MASK to grow within the country MASK sphere → Western music’s effect would continue to grow within the MASK MASK sphere.
Baselines
- BiLSTM-CRF: Bi-directional LSTM + Conditional Random Field
- Coach (A Coarse-to-Fine Approach): It splits the sequence labeling task into two stages by first detecting the entities and then categorizing the detected entities.
- Cross-Domain Language Modeling: Jia, Liang, and Zhang (2019) integrated language model- ing tasks and NER tasks in both source and target domains to perform cross-domain knowledge transfer.
- Multi-Cell Compositional LSTM: Jia and Zhang (2020) proposed a multi-cell compositional LSTM structure based on BERT representations for NER domain adaptation.
Results & Analysis
Main Results
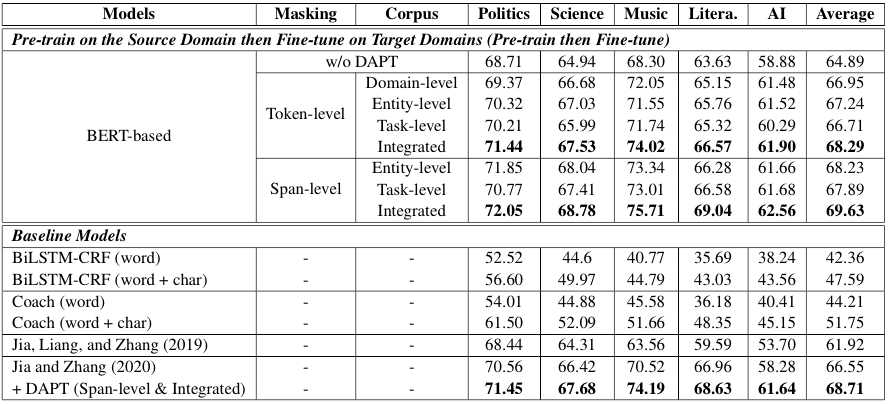
- DAPT using the entity-level or the task-level corpus achieves better or on par results with using the domain-level corpus.
- Span-level pre-training consistently outperforms token-level pre-training.
- DAPT is able to improve upon the previous SOTA model (Jia and Zhang 2020).
Performance over Target Domain Sample Size
Few-shot results on the music domain. Pre-train then Fine-tune denotes Pre-train on the Source Domain then Fine-tune on Target Domains; Joint Train denotes Jointly Train on Both Source and Target Domains; Directly Fine-tune denotes Fine-tune Directly on Target Domains.
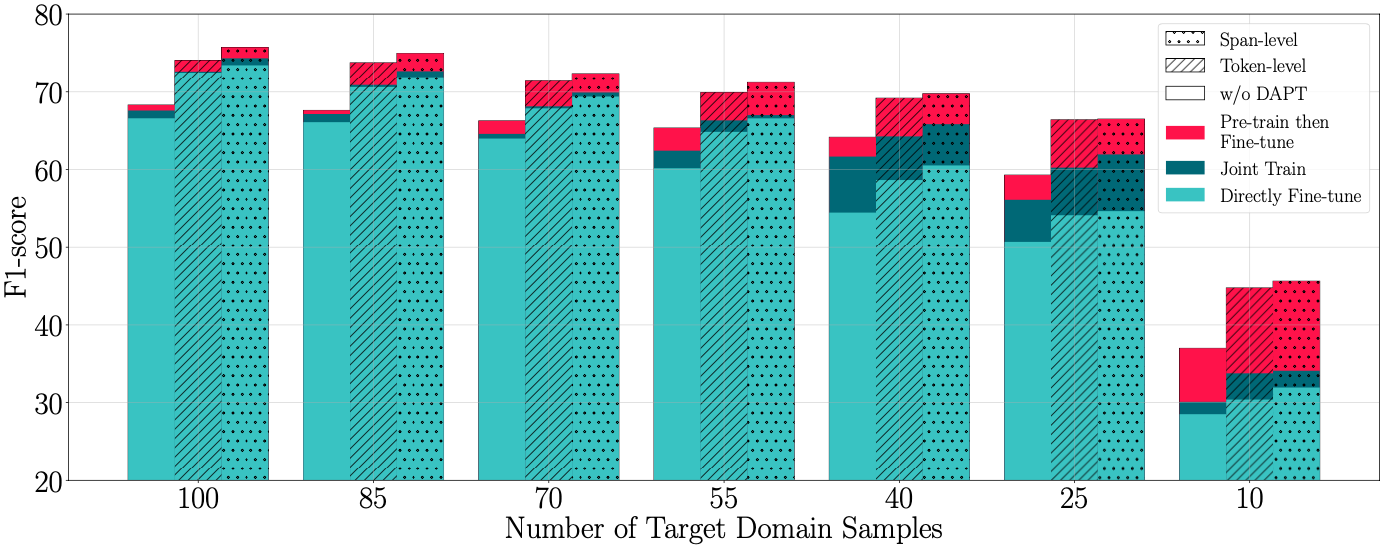
- The task becomes exceptionally difficult in the extremely low-resource setting (e.g., 10 samples are available).
- As the target domain sample size decreases, the advantage of using source domain training samples becomes more significant.
- Using DAPT significantly improves the performance in the Pre-train then Fine-tune setting when target samples are scarce (e.g., 10 samples).
- With the decreasing of the sample size, the performance discrepancy between Pre-train then Fine-tune and Jointly Train is getting larger.
Performance over Unlabeled Corpus Size
Comparisons among utilizing different percentages of the music domain’s integrated corpus and masking strategies in the DAPT for the three settings.
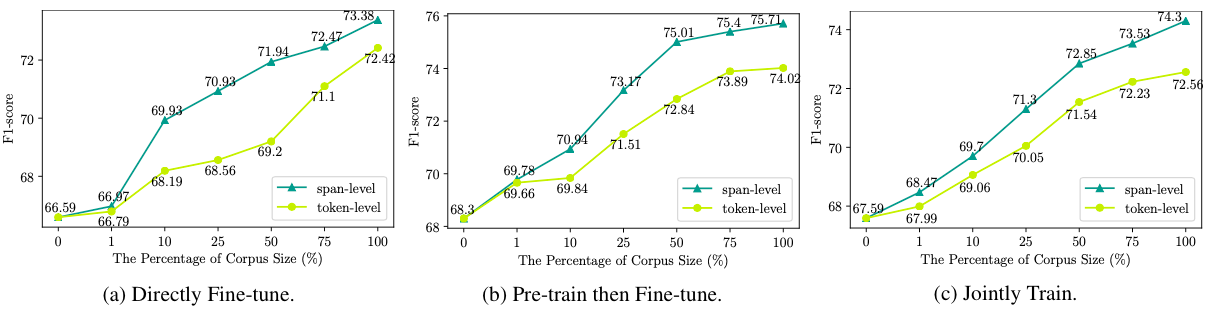
- The performance generally keeps improving as the corpus size increases.
- Span-level pre-training loses its effectiveness when only a small-scale (e.g., 1% of the corpus) is available. As the corpus size increases, the span-level masking starts to outperform the token-level masking.
Conclusion and Future Work
In this blog, we introduce CrossNER, a fully-labeled collection of NER data spanning over five diverse domains with specialized entity categories for different domains. Moreover, the experimental results and analyses are provided for DAPT. Finally, we highlight the potential research directions for this area: 1) How to extract effective sentences for the DAPT; 2) Exploring different pre-training strategies for the DAPT; 3) More advanced models are needed to cope with the extremely low-resource settings.
Other Notes
You can refer to the CrossNER paper (accepted in AAAI-2021) for the details of the related work, the collection process of CrossNER, experimental results and analyses. The data and baselines are available under our Github repository.